B2B SaaS · Analytics Platform
EduFeedbackPro
Analytics platform for student performance, focused on transforming fragmented data into actionable signals through structured data modelling and real-time aggregation.
reports 3min to <10s

Intro
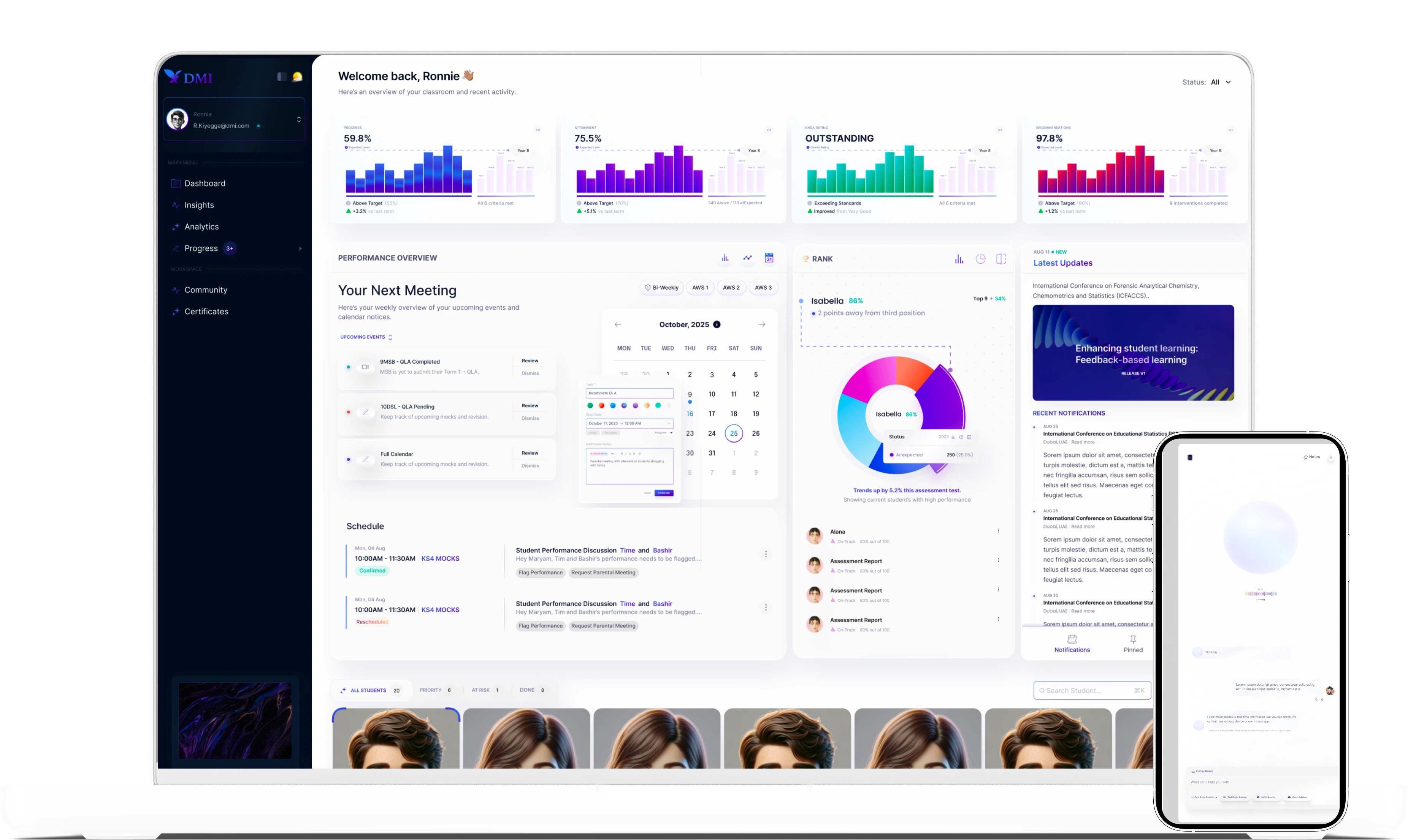
EduFeedbackPro is an internal analytics tool for secondary schools. The main issue I was dealing with was how fragmented the data was. It already existed, but it lived across exports, MIS systems, and spreadsheets, so staff had to piece things together manually. I built the UI and the data path from Postgres and BigQuery out to the browser, including real-time updates with SSE.
- Role-based access across departments
- Single student/cohort model instead of manual reconciliation across systems
- Next.js 15, Prisma, Neon Postgres, BigQuery, Docker, Playwright on critical paths
- Runs in production, so performance and failure modes had to be handled properly
Performance highlights
The dashboards are used throughout the day, so I needed reads to stay fast without putting pressure on Postgres. I kept analytical queries in BigQuery so the main database could handle user-facing work without getting blocked.
- Target low-latency reads once caches are warm
- No polling; updates are pushed via SSE when data changes
- Notifications arrive shortly after changes are written
- Postgres handles auth, enrolment, and writes; BigQuery handles heavier analytical queries
Problem
The core problem wasn't lack of data, it was how hard it was to use. Marks and cohort data were spread across different systems, and staff had to reconcile everything manually. That made it slow to spot issues, and most insights only showed up after the fact.
- Same student represented differently across sources, leading to duplication
- Reports were batch-based, so insights arrived late
- No shared signal for when something needed attention
- Anything derived still had to map back to numbers people trusted
Solution
I structured the system around how staff already think about the data: students, cohorts, and assessments, with dashboards built on top. Instead of relying on manual refresh, the server pushes updates when something changes.
- Dashboards surface patterns earlier instead of at the end of term
- Server builds BigQuery queries from UI actions; no direct query access from the client
- Voice input is optional; all workflows work without it
- RBAC scoped by department to keep data isolated between groups
Real-time architecture
Most of the traffic is server to client, so I didn't need WebSockets. SSE was enough for pushing updates without adding extra complexity.
- Events emitted on domain changes (enrolment, assessment, notifications)
- In-memory subscription layer, with a path to Redis if needed later
- Reconnection and backoff tuned for unreliable networks
- Heartbeats to keep long-lived connections alive
System architecture
I split transactional and analytical workloads so they don't interfere with each other. Postgres handles user data and writes. BigQuery handles heavier analytical queries.
- Next.js Route Handlers for APIs and SSE streams
- Prisma on Postgres, with a clear boundary for BigQuery calls
- Docker for consistent deploys; Sentry for production monitoring
- Short TTL for notifications, longer TTL for expensive analytical reads
Key engineering decisions
Most decisions came down to keeping things simple while handling real-time updates and read-heavy traffic.
- Used SSE because updates are one-way; WebSockets weren't necessary
- Split databases so analytical queries don't affect transactional performance
- Kept query generation on the server instead of exposing SQL to clients
- Treated voice as optional, not something required to use the system
Tradeoffs
Some of the simpler choices come with limits, especially around scaling and data freshness.
- In-memory pub/sub works for a single instance; scaling would require Redis
- TTL caching reduces load but introduces some staleness
- Postgres and BigQuery need consistent schemas; UI can't compensate for that
- SSE is one-way; real-time collaboration would need a different approach